Remove Duplicates from List Python
Working with lists is a common task in Python. Sometimes we need to remove duplicate elements from a list.
Whether you are ensuring unique elements in a list or clearing data for further processing, removing duplicates from a list is a common task.
Here you will learn multiple different ways to remove duplicates from a list in Python.
1. Using set() method
set() method is the easiest way to remove duplicates from a list. It removes all the duplicate elements from the list and returns a set of unique elements.
You can later convert this set back to a list using the list() method.
my_list = ['a', 'b', 'a', 'c', 'd', 'b', 'a', 'c', 'e']
# converting list to set
my_set = set(my_list)
# converting set back to list
my_new_list = list(my_set)
print(my_new_list)Output: (It can be in any order)
['c', 'a', 'e', 'd', 'b']
As you can see, all the duplicate elements are removed from the list.
But there is a problem with this method. It changes the order of elements in the list. If you want to preserve the order of elements, you can use the OrderedDict method.
2. Using OrderedDict method
OrderedDict is a dictionary subclass that remembers the order in which the elements were added. It is available in the collections module.
So, we can use this property of OrderedDict to remove duplicates from a list while preserving the order of elements.
First, we will convert the list to an OrderedDict and then convert it back to a list.
from collections import OrderedDict
my_list = ['a', 'b', 'a', 'c', 'd', 'b', 'a', 'c', 'e']
# converting list to ordered dict
my_ordered_dict = OrderedDict.fromkeys(my_list)
# converting ordered dict back to list
my_new_list = list(my_ordered_dict)
print(my_new_list)Output:
['a', 'b', 'c', 'd', 'e']
As you can see, the order of elements is preserved.
3. Using list comprehension
List comprehension is a single tool that can be used to perform multiple operations on a list.
You can also use this to remove duplicates from a list.
my_list = ['a', 'b', 'a', 'c', 'd', 'b', 'a', 'c', 'e']
# using list comprehension
my_new_list = [i for n, i in enumerate(my_list) if i not in my_list[:n]]
print(my_new_list)Output:
['a', 'b', 'c', 'd', 'e']
Here, we are iterating over the list and checking if the current element is not present in the list before the current element. If it is not present, we are adding it to the new list.
4. Using for loop
Using a for loop is the most basic way to remove duplicates from a list.
Here, we will iterate over the list and check if the current element is not present in the new list. If it is not present, we will add it to the new list.
my_list = ['a', 'b', 'a', 'c', 'd', 'b', 'a', 'c', 'e']
# using for loop
my_new_list = []
for i in my_list:
if i not in my_new_list:
my_new_list.append(i)
print(my_new_list)Output:
['a', 'b', 'c', 'd', 'e']
5. Using dict.fromkeys() method
dict.fromkeys() method is used to create a new dictionary from a given sequence of elements.
Since a dictionary cannot have duplicate keys, we can use this property to remove duplicates from a list.
Later we can convert this dictionary back to a list.
my_list = ['a', 'b', 'a', 'c', 'd', 'b', 'a', 'c', 'e']
# converting list to dictionary
my_dict = dict.fromkeys(my_list)
# converting dictionary back to list
my_new_list = list(my_dict)
print(my_new_list)Output:
['a', 'b', 'c', 'd', 'e']
6. Using numpy.unique() method
numpy.unique() method returns the unique elements from a list.
It also returns the indices of the elements in the original list.
So, we can use this method to remove duplicates from a list.
import numpy as np
my_list = ['a', 'b', 'a', 'c', 'd', 'b', 'a', 'c', 'e']
# using numpy.unique() method
my_new_list, indices = np.unique(my_list, return_index=True)
print(my_new_list)Output:
['a' 'b' 'c' 'd' 'e']
Here, we are also returning the indices of the elements in the original list. You can use these indices to get the elements from the original list.
import numpy as np
my_list = ['a', 'b', 'a', 'c', 'd', 'b', 'a', 'c', 'e']
# using numpy.unique() method
my_new_list, indices = np.unique(my_list, return_index=True)
print(my_list[indices])Output:
['a' 'b' 'c' 'd' 'e']
7. Using pandas.drop_duplicates() method
pandas.drop_duplicates() method is used to remove duplicate rows from a DataFrame.
This can be a handy method if you are working with dataframes.
import pandas as pd
my_list = ['a', 'b', 'a', 'c', 'd', 'b', 'a', 'c', 'e']
# using pandas.drop_duplicates() method
new_list = pd.Series(my_list).drop_duplicates().tolist()
print(new_list)Output:
['a', 'b', 'c', 'd', 'e']
Conclusion
These are some of the ways to remove duplicates from a list in Python. You can use any of these methods depending on your use case.
But if you are working with a large list, you should use the set() method as it is the fastest method to remove duplicates from a list.
Here is a speed comparison of all the methods discussed above.
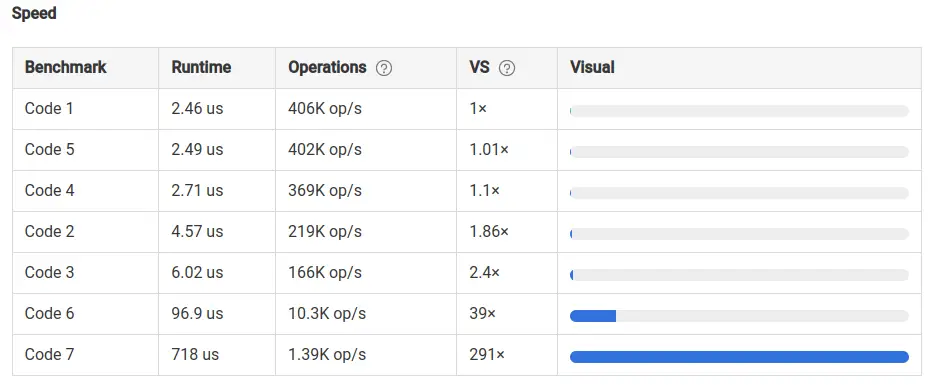
You can clearly see fastest way to remove duplicates from list python is using set() method.